
어떤 선생님이 읽으면 좋을까요?
객관적이면서 타당한 채점 기준을 세우고 싶은 선생님
AI를 활용하여 채점 과정을 효율화하고 싶은 선생님
채점 후 이의 대응에 대해 고민이 많은 선생님

요약
기본 정보
학년: 고등학교 2학년
주제: 쓰기 수행평가 채점기준 설계 및 채점 진행
AI 활용 내용
교사의 루브릭을 적용한 채점 자동화
채점 기준 정교화
왜 AI 채점을 고민하게 되었나요?
쓰기 수행평가 채점 과정에서 가장 큰 고민은, 정량화하면 객관성은 확보되지만 작문 수준을 질적으로 변별하지 못한다는 점이였습니다.
초기에는 '객관적인 루브릭을 어떻게 설계할 것인가'에 대한 고민이 많았습니다. 쓰기 수행평가의 결과에 대해 늘 이의 신청이 많았고, 교사가 아무리 좋은 루브릭을 사용하더라도 채점 과정에 교사의 주관이 개입될 수 밖에 없다는 점에서 학생들에게 평가가 객관적이지 못하다는 인상을 심어주는 것 같았습니다.
이에 다음과 같은 구조로 수행평가를 운영했습니다.
<수행평가 내용>
Target Grammar 패턴 드릴 빈칸 채우기
해당 패턴을 활용한 자신의 문장 만들기
6~7문장 분량의 Guided Writing
<채점 기준>
학습한 어법 패턴이 포함되면, 문장이 완벽하지 않더라도 해당 패턴을 사용한 것으로 인정
필수 어법과 무관한 부분에서 오류가 있더라도 주어·동사 구조만 갖추면 문장으로 인정
내용이 부실하더라도 빈칸을 채우면 한 문장으로 인정
모든 빈칸이 기준에 맞게 채워지면 만점, 미충족 빈칸 수만큼 감점
이 방식에는 수치적 객관성은 분명히 있었으나, 다음과 같은 문제가 있었습니다.
주제에 부합하지 않는 글도 점수를 받을 수 있음
어법적으로 완전한 문장이 구성되지 않아도 점수를 받을 수 있음
복잡한 문장구조를 사용한 우수 학생과 단문을 나열한 학생이 동일 점수를 받음
충분한 분량의 글을 쓰지 않아도 점수 확보 가능
글의 기본 구조를 무시해도 점수를 받을 수 있음
결국 제가 중요하게 생각했던 쓰기 평가 채점 요소인 주제 적합성, 어법 정확성, 문장 복잡성, 글의 구성 요소, 글의 분량은 충분히 반영되지 못한 채 정량화에만 초점이 맞춰졌고, 우수한 학생과 그렇지 못한 학생의 작문 수준을 질적으로 변별하지 못한다는 문제는 계속 남아 있었습니다.
이런 고민이 이어지던 시기에 AI 기술이 빠르게 발전하기 시작했습니다. ChatGPT를 비롯한 생성형 AI를 보면서, 작문의 질적 평가와 정량적 평가를 통합할 수 있지 않을까 생각하게 되었습니다. 문장 수나 어법 정확성처럼 수치화할 수 있는 요소는 정량적으로 평가하고, 주제 적합성이나 문장 복잡성은 분석 기반으로 판단할 수 있다면 기존의 한계를 보완할 수 있겠다고 판단했습니다.
그 과정에서 플랭스쿨을 알게 되었고, 정량성과 타당도를 동시에 가져갈 수 있는 수행평가 모델을 다시 설계해 보고자 했습니다.
수행평가 안내 및 진행 방법
수행평가는 다음과 같이 운영했습니다.
수행평가 2개월 전, 작문 주제와 세부 채점 기준, 유의 사항을 사전 공지
사전에 채점 기준을 플랭 AI에 입력하여 자동 채점이 가능하도록 설정
연습 수행평가(데모 버전)를 제공하여 플랭스쿨 인터페이스에 미리 익숙해질 기회 제공
수행평가는 40분 동안 플랭스쿨에서 직접 타이핑하여 제출하도록 운영
<부정행위 및 재응시 기준>
플랭스쿨 사이트 이외의 웹페이지 또는 다른 프로그램이 열려 있는 경우 부정행위로 처리
명확한 기기 오류(와이파이 끊김, 기기 정지 및 재부팅 등)의 경우 재응시 기회 부여
기기 배터리 부족은 재응시 사유로 인정하지 않음
<채점 및 이의 신청 절차>
학생 제출 즉시 플랭 AI를 통해 자동 채점 제공
점수에 대한 이의 신청은 수행평가 시간 종료 전까지만 접수
종료 전 이의 신청 의사를 밝힌 경우, 종료령이 울린 이후에도 이의 내용을 청취
이의 내용이 타당하다고 판단될 경우 점수 수정
채점기준 설정
가장 고민이 많았던 부분은 채점 기준이었습니다.
학생들의 우수함과 부족함을 최대한 객관적으로 수치화할 수 있는 기준을 설정하고자 했습니다.
작문 평가에 반영한 요소는 다음과 같았습니다.
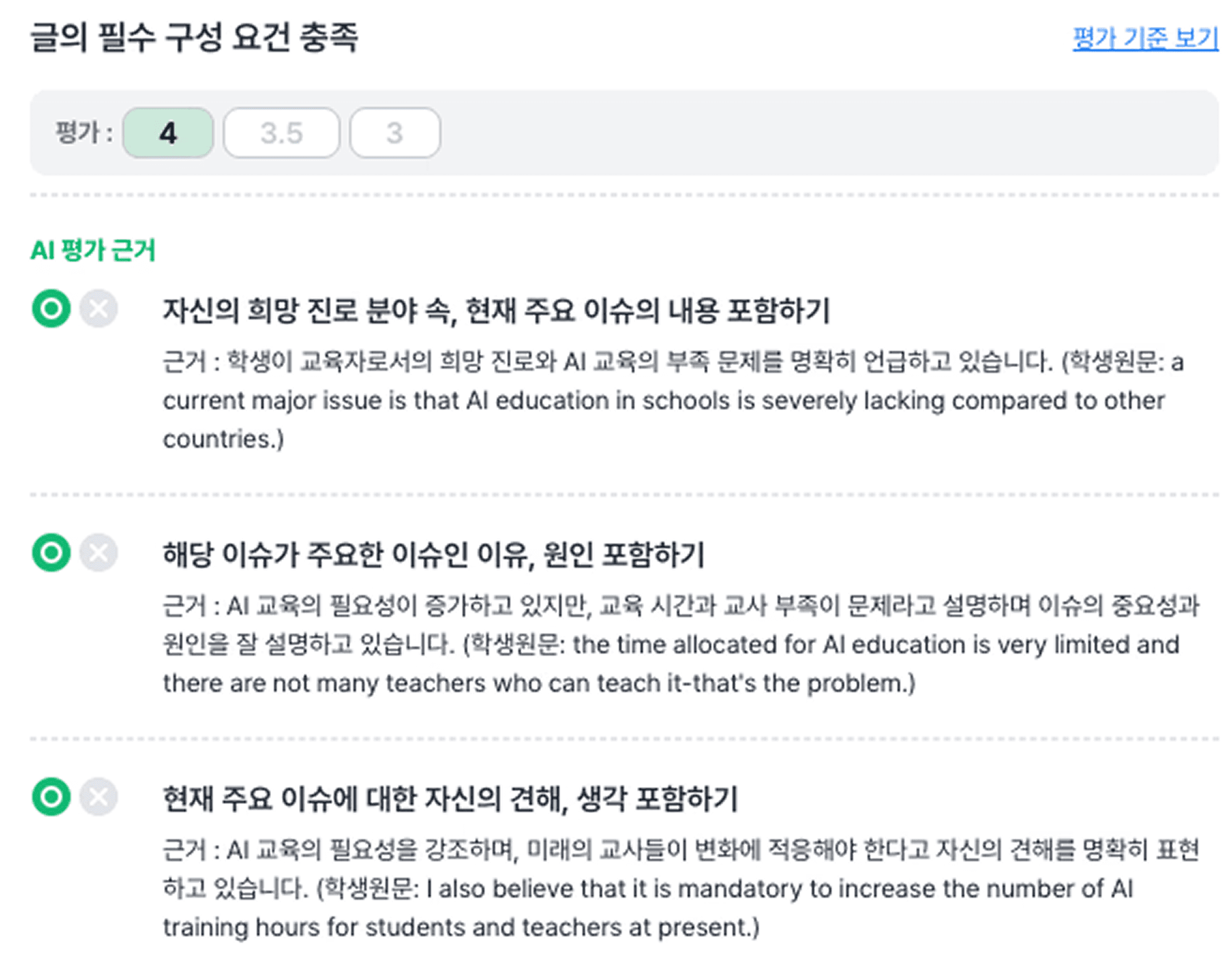
글의 필수 구성 요소 포함 여부
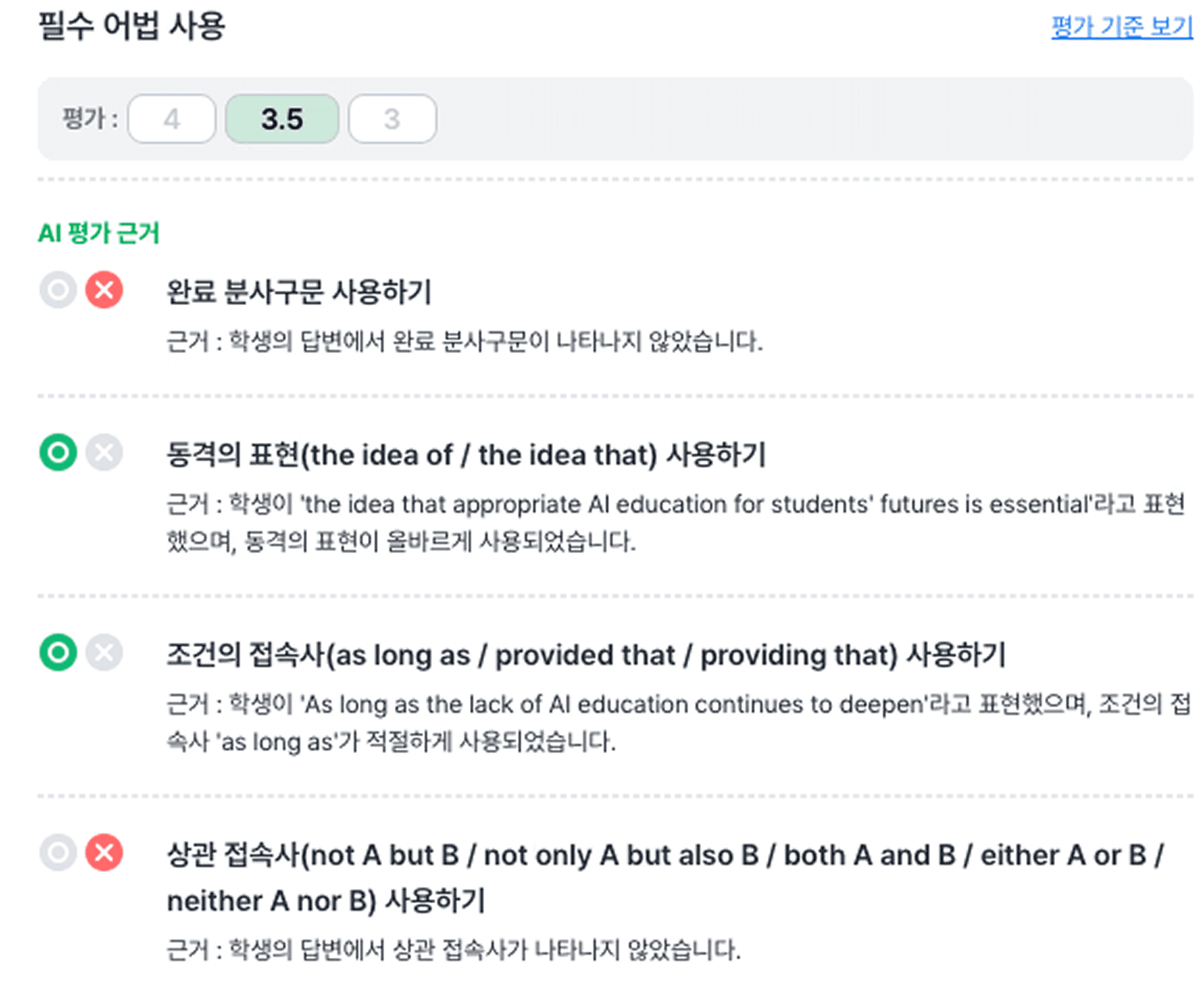
필수 어법 사용 여부
문장 수
어법 정확성
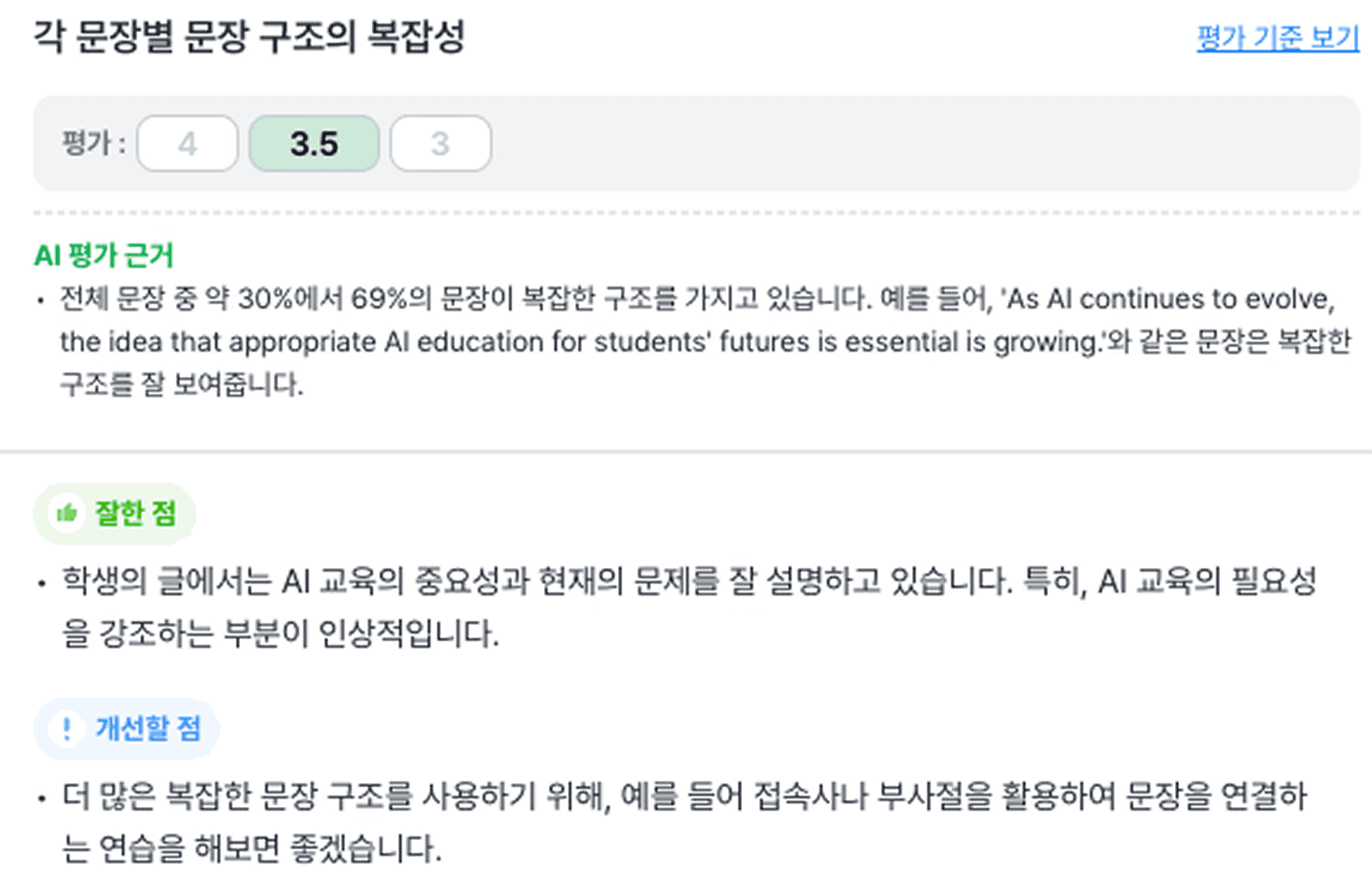
문장 복잡성
주제 연관성
채점 기준의 세부 사항을 설정할 때는 AI조차 일관되게 판단하기 어려운 주관적 평가 표현(매우 잘함, 우수함, 뛰어남, 미흡함, 부족함, 다소, 적절한 등)은 배제하고, 정확한 수치나 데이터의 유무로 판단을 내릴 수 있는 기준을 만들고자 했습니다.
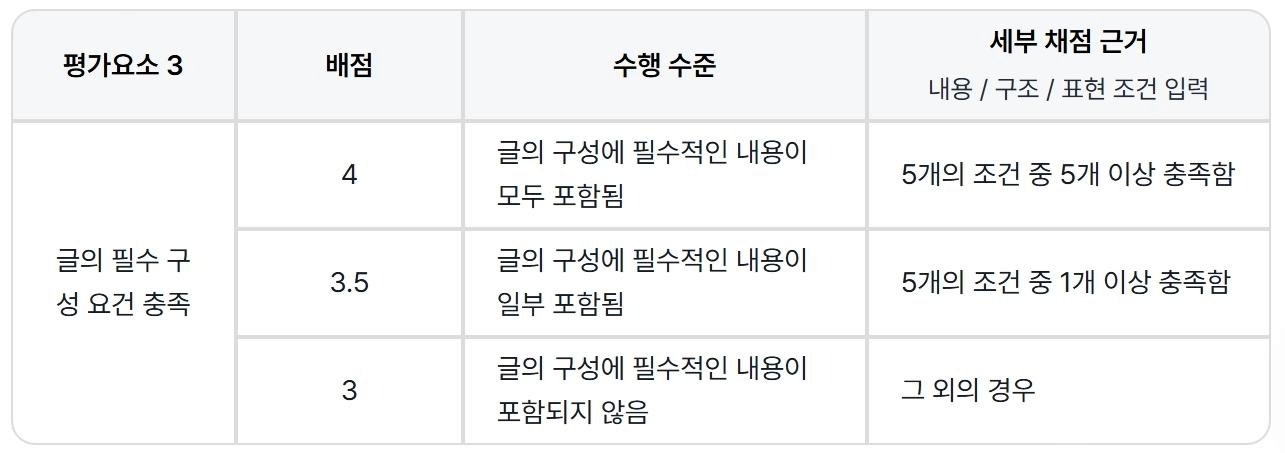
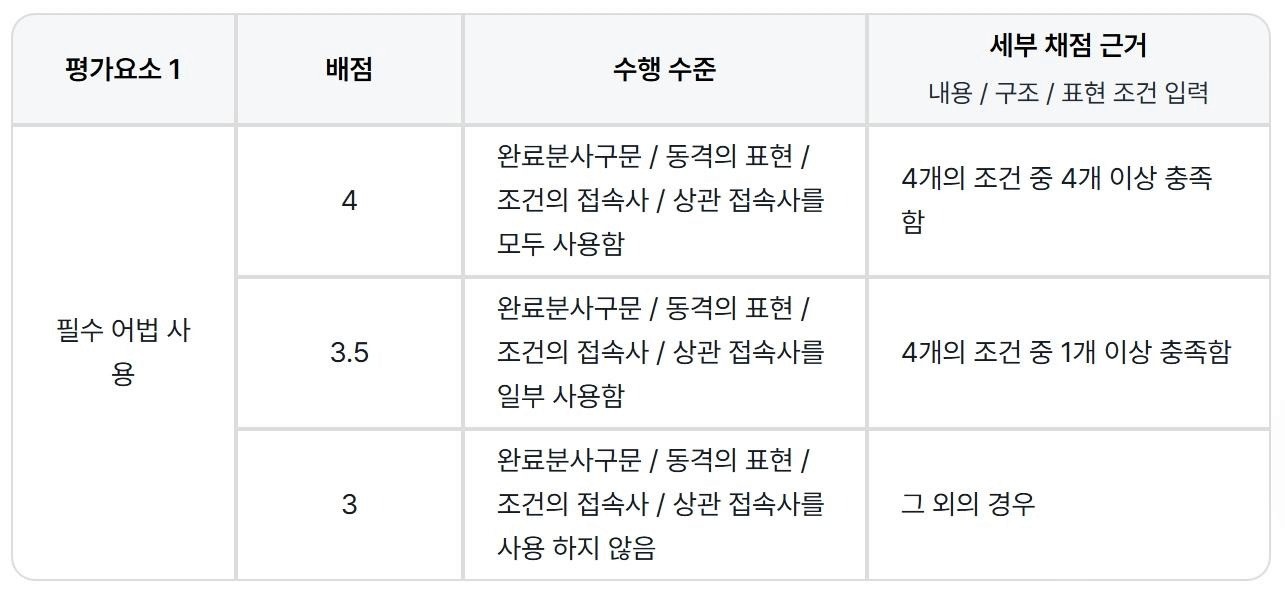
글의 필수 구성 요소, 필수 어법, 문장 수의 경우에는 플랭 AI가 안정적으로 카운팅할 수 있다고 판단하여 아래와 같이 채점 기준을 설정했습니다. 세부 채점 근거로 구체적인 조건을 입력하면, 각 조건에 대한 충족 여부를 플랭 AI가 O/X로 판단하고, 그에 맞는 가채점을 해주는 식입니다.
<정량적으로 판단 가능한 요소>
글의 필수 구성 요소, 필수 어법, 문장 수의 경우에는 플랭 AI가 안정적으로 카운팅할 수 있다고 판단했습니다.
이에 플랭스쿨의 세부 채점 근거 기능을 활용하여, 플랭 AI에 구체적인 조건을 입력하고 충족된 항목에 따라 자동 가채점이 이뤄지게 했습니다.

<비율 기반으로 판단한 요소>
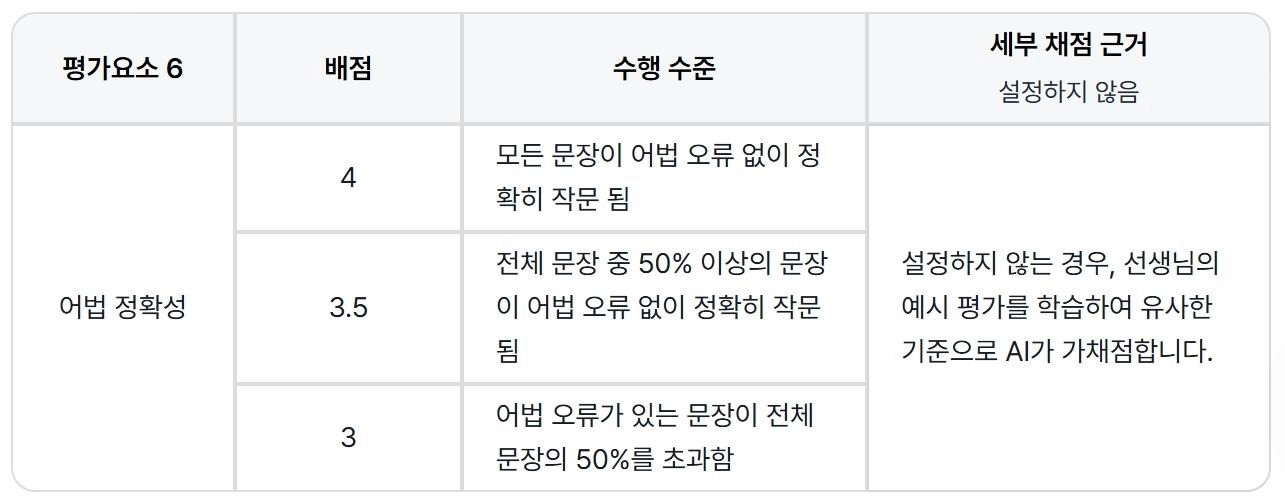
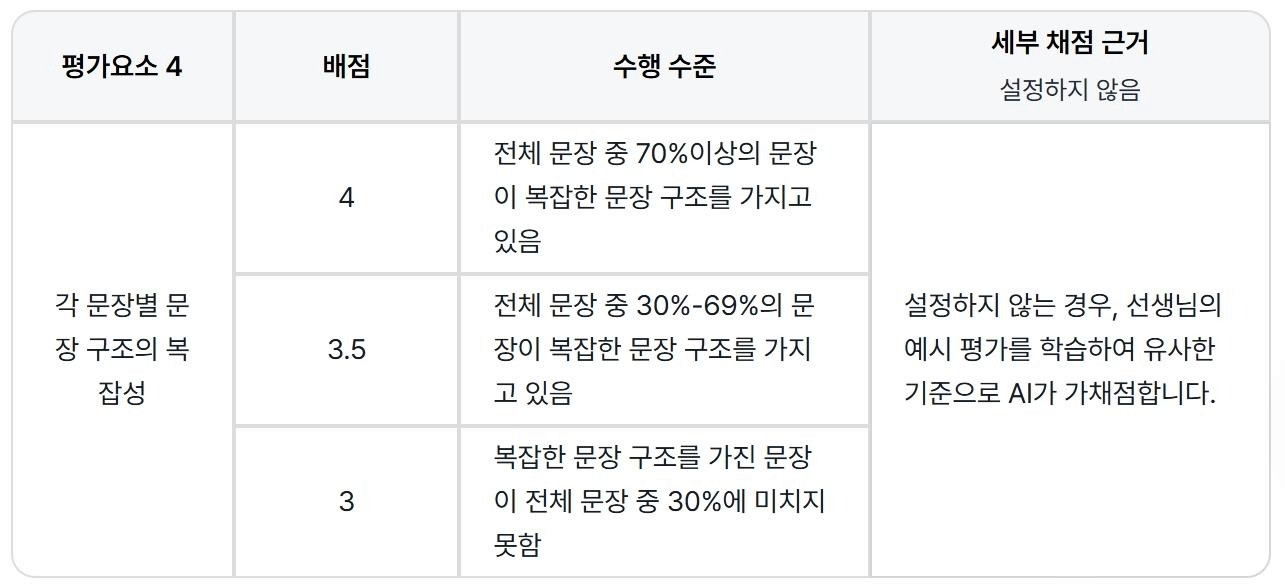
어법 정확성과 문장 복잡성은 '비율'로 판단하도록 설계했습니다.
어법 정확성 : 전체 문장 중 어법 오류가 없는 문장의 비율
문장 복잡성 : 전체 문장 중 복잡한 구조로 판정되는 문장의 비율
<주제 연관성>
주제 연관성의 경우, 전체 글의 주제 통합성으로 판단하기보다는 주제와 관련 없다고 판정되는 문장 포함 여부로 채점하는 기준을 설정했습니다.
이러한 채점 기준을 설계하기 전, 플랭 AI가 각 요소를 안정적으로 인식하는지 사전 테스트 과정을 거쳤습니다. 다양한 예시 작문을 입력해 인식 오류 여부를 확인하고, 기준을 수정·보완한 뒤 온라인 수행평가를 진행했습니다.
자동 채점
학생이 작문을 타이핑해 제출하면, 학생들은 아래와 같이 채점 결과를 바로 확인할 수 있었습니다.

채점기준 정교화 및 학생 이의 처리
이의 가능성은 여전히 있기에, 아래의 과정으로 이의 신청을 받았습니다.
발생한 이의 유형은 크게 아래의 유형이 있었습니다.
필수 어법 인식 오류 n건
문장 수 카운팅 오류 1건
주제 연관성, 문장 복잡성, 어법 정확성 관련 이의 3건
필수 어법 인식 오류와 문장 수 오류의 경우, 교사가 직접 읽고 확인해도 채점 결과의 객관성을 훼손시키지 않는다고 판단하여 큰 문제가 없었지만, 주제 연관성, 문장 복잡성, 어법 정확성의 경우에는 교사가 직접 다시 읽고 판단하는 순간 주관이 개입된다고 판단했습니다.
이에 주제 연관성, 문장 복잡성, 어법 정확성 영역에 대해서는 Chat GPT Pro에게 채점 기준을 학습시킨 후, 재채점을 진행했습니다. 단, 학생들에게 조건을 분명히 했습니다.
ChatGPT Pro를 활용한 재채점 결과를 무조건 수용
점수가 오히려 낮아질 때도 해당 점수를 그대로 반영
ChatGPT Pro에게 채점 기준을 학습시킨 방법은 다음과 같았습니다.
① 재채점할 영역을 설정(주제 적합성, 문장 복잡성, 어법 정확성)
② 세 개의 영역에 대해 플랭에서 만점을 받은 학생들의 우수 작문 사례 19편을 ChatGPT Pro에 입력하여 앞으로 채점할 글과 비교, 분석할 기준글로 설정
③ 플랭에서 학생들이 직접 작문한 다양한 점수대의 글을 무작위로 ChatGPT Pro에 입력하여 일단 재채점을 진행
④ 입력한 지문에 대한 ChatGPT의 평가 점수와 플랭에서의 평가 점수를 비교
⑤ 둘 간의 점수가 다른 경우에는 그 이유에 대해서 ChatGPT에게 물어보고, 채점 기준을 보정, 상세화, 정량화하도록 지시
⑥ 채점 정확도가 만족할 만한 수준에 도달할 때까지 위 과정을 반복
⑦ 만족할 수준이 되었을 때, 정립된 채점 기준을 출력하도록 한 후, 이를 검토하여 최종 수정 및 확정.
⑧ 이의 학생의 글에 대한 재채점을 진행.
Chat GPT를 활용해 정교화한 평가 기준은 다음과 같았습니다.
✅ 영어 작문 채점 기준 (2025.06 확정판)
📋 평가 항목 (총 3개, 각 항목 4.0점 만점)
주제 연관성 (Relevance to the Topic)
문장 복잡성 (Sentence Complexity)
어법 정확성 (Grammatical Accuracy)
1. 🟩 주제 연관성
평가 요소
글의 시작 부분에서 미래 진로/직업/계획이 명확히 제시되었는가?
주제에 맞는 동기, 관심, 실천 내용이 구조적으로 잘 연결되어 있는가?
고등학생 수준에서의 진로 불확실성(직업 표현의 추상성 등)은 감점 요소가 아님
점수 기준
점수 | 판단 기준 |
|---|---|
4.0점 | 미래 계획 또는 직업이 명확하게 제시되며, 실천 내용과의 연결이 논리적이고 일관됨 |
3.5점 | 전체적인 흐름은 있지만, 직업 명시가 불분명하거나 실천 내용과의 연결성이 약함 |
3.0점 | 진로 주제가 명확하지 않거나, 실천 내용이 연결되지 않음 |
2. 🟨 문장 복잡성
복잡한 문장으로 인정되는 구조 (✔︎)
관계절 (who, which, that)
전치사 + 관계사 (in which, through which 등)
분사구문 (Motivated by~, Influenced by~ 등)
명사절, 부사절 (that절, if절, because절 등)
병렬 구조 중첩 (절이 2개 이상 결합된 문장)
복합 조건문, 부사구 포함 복문 등도 포함 가능 (판단자의 유연한 판단 허용)
정량 기준
복잡한 문장 비율 | 점수 |
|---|---|
70% 이상 | 4.0점 |
30% ~ 69% | 3.5점 |
30% 미만 | 3.0점 |
※ 전체 문장 수 대비 복잡한 문장 수로 비율 계산
3. 🟥 어법 정확성
어법 오류에 포함되는 항목 (✔︎)
주어-동사 불일치
시제 오류
관사, 전치사, 관계사 오용
관계절/분사구문/접속사 구조 오류
주어 생략된 문장, 문장 연결 오류(comma splice 등)
어순 오류로 의미 해석이 불가능한 경우
단순 어색함은 오류 아님 (🟡)
표현이 자연스럽지 않지만 문법적으로는 틀리지 않은 경우
예: “I improved my English ability.” → 자연스럽진 않아도 감점 없음
정량 기준
오류 문장 비율 | 점수 |
|---|---|
0% | 4.0점 |
1% ~ 50% | 3.5점 |
50% 초과 | 3.0점 |
※ 전체 문장 수 대비 명백한 오류가 있는 문장 수 기준
📌 기타 원칙
모든 항목은 독립적으로 평가 (한 항목의 점수가 다른 항목에 영향을 주지 않음)
**기준글(4점 작문 예시)**과의 상대 비교는 판단 보조 수단으로 사용
채점은 언제나 최신 기준에 따라 독립적으로 다시 평가 가능
배한제 선생님의 코멘트
플랭을 활용한 쓰기 수행평가를 운영하면서 기존의 빈칸 중심, 형식 중심 쓰기 수행평가보다는 분명히 질적 변별력이 개선되었다고 느꼈습니다. 또한 AI를 활용함으로써 이전보다 객관적이고 정량화된 평가를 진행할 수 있게 되었습니다. 특히 매우 구체적인 평가 레포트가 즉각적으로 제공되면서, 학생들이 자신의 점수와 오류를 확인하고 이해할 수 있었고, 그 결과 수행평가에 대한 수용도도 높아졌습니다.
다만 “원클릭으로 모든 것이 해결된다”라는 기대는 적절하지 않다고 생각합니다. 플랭이 자동으로 채점해 준다고 해서 교사의 역할이 줄어드는 것은 아니었습니다. 오히려 더 정교한 채점을 위해 교사가 채점 기준을 끊임없이 고민해야 했습니다. 수행평가를 실제로 적용하기 전에 플랭에 여러 차례 시뮬레이션을 해보며, 제가 의도한 수준의 평가 정확도가 나오는지 확인했고, 필요할 때마다 기준을 미세 조정하고 구체화하는 과정을 반복했습니다. 결국 도구보다 중요한 것은 교사가 설정한 기준이었습니다.
또 한편으로는, 점수 중심의 정량화에 지나치게 초점을 맞춘 것이 아니냐는 비판이 가능하다는 점도 충분히 공감합니다. 실제로 100자 남짓한 글로 만점을 받은 학생도 있었고, 200자를 훨씬 넘는 분량을 작성하고도 동일하게 만점을 받은 학생도 있었습니다. 이런 상황을 놓고 보면, 서두에서 언급했던 ‘우수 학생의 변별’ 문제는 완전히 해소되었다고 보기는 어렵습니다.
하지만 저는 이러한 차이는 수행평가 점수라는 수량적 지표로 구분하기보다는, 다른 방식으로 드러내는 것이 더 적절하지 않을까 생각하게 되었습니다. 저는 교과세부능력특기사항을 작성할 때, 학생들의 작문 수준, 구조의 정교함, 준비 과정의 성실함과 고민의 깊이를 반영하고 있습니다. 점수로는 동일하게 보일지라도, 서술 기록을 통해 학생의 실제 역량 차이를 드러내는 방식입니다.
“교사의 주관은 곧 객관이다.”라는 말을 떠올리게 됩니다. AI 채점이 교사의 주관을 배제하는 것이 아니냐는 우려도 있을 수 있습니다. 하지만 저는 오히려 반대로 생각합니다. 의도한 바가 반영된 객관적 채점 기준을 설정하기 위해 고민하고, 수정하고, 반복 검증하는 과정 속에 교사의 교육 철학과 주관적 판단이 충분히 녹아 들어가 있다고 봅니다. AI는 그 기준을 실행하는 도구일 뿐, 기준을 세우는 주체는 여전히 교사라고 생각합니다.
객관적이고 정량적인 평가기준을 활용한 AI 기반 쓰기 수행평가를 고민하고 계신 선생님들께 하나의 운영 사례로 참고가 되었으면 합니다.


